Aurora Turns Video Editing Into A Tool-Using AI Workflow Instead Of A One-Prompt Gamble
Release Overview
A fresh video-model release from May 18, 2026 deserves attention because it tackles one of the most practical failure points in generative video editing. Aurora is not just another unified video diffusion model. It is an agentic editing stack that pairs a tool-using vision-language model with a video transformer so the system can first resolve what the user actually meant, then execute the edit. That makes the release more useful than a typical benchmark-oriented launch, because real editing prompts are usually incomplete, visually underspecified, or missing assets the model needs.
The Hugging Face paper page and the GitHub repository both frame the same core idea: users often ask for a change without providing model-ready reference images, masks, or precise edit language. Aurora inserts a reasoning layer before generation. Instead of trusting the raw prompt, the VLM agent rewrites it into a typed edit plan aligned with the downstream video diffusion model. In practical terms, that means the release is trying to turn video editing from a prompt lottery into a more reliable workflow.
What Aurora Actually Changes
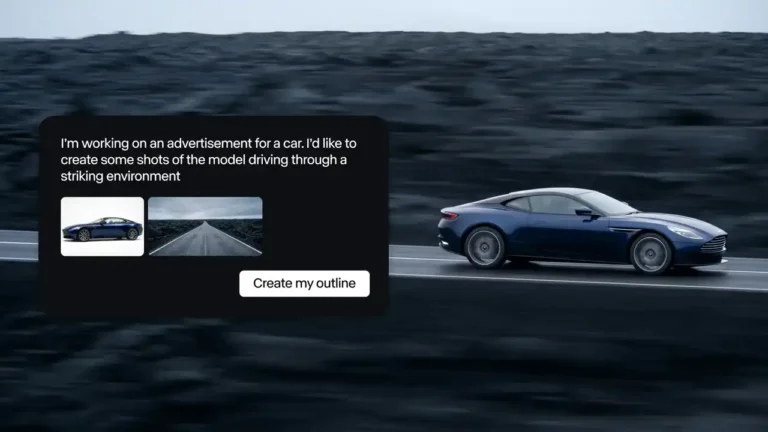
The technical shift is straightforward but important. According to the paper, Aurora's agent converts a user request into four concrete fields: instruction, task label, image-search query, and mask phrase. That structured plan is then passed to a unified video diffusion transformer that can handle replacement, removal, style transfer, and reference-driven insertion. The design matters because it acknowledges a fact many consumer AI tools still ignore: human editing requests are often semantically clear to another person but operationally incomplete for a model.
The GitHub README adds a second useful detail. Aurora is built to fill missing reference images through web image search and missing masks through grounded segmentation. That means the model is not only interpreting a prompt more carefully. It is also using tools to fetch the missing context required to perform the edit well. In AI product terms, that is a stronger design pattern than simply making the diffusion model larger and hoping the ambiguity disappears.
What This Model Is Useful For
| Use Case | Why It Fits | Practical Output |
|---|---|---|
| Prompt-to-edit planning | Aurora rewrites raw requests into typed edit plans before generation. | Cleaner editing prompts for replacement, removal, style transfer, or insertion tasks. |
| Reference-driven video editing | The agent can search for missing reference imagery when the prompt is incomplete. | More consistent subject replacement or style matching without forcing the user to pre-assemble assets. |
| Localized edit workflows | The system uses mask phrases and grounded segmentation to fill missing spatial guidance. | Edits that better target specific objects or regions within a clip. |
| Tool-augmented creative systems | Aurora is designed around a VLM agent plus external tools rather than one isolated generator. | A reusable architecture for next-generation creator software and editing copilots. |
Why The Benchmarks Matter
Aurora also comes with a benchmark story that fits the product claim. The paper introduces AgentEdit-Bench, a benchmark built around textual and visual underspecification in video editing. That is significant because many current video-editing evaluations assume the prompt is already well formed and that the reference material is already in place. Aurora is evaluated on the harder scenario where the user request is under-specified, which is much closer to how creators actually interact with editing tools.
The public materials say Aurora improves over instruction-only baselines and that the agent transfers to compatible frozen video editing models. That transfer claim is strategically important. If the reasoning layer can sit in front of other editing backbones, then Aurora is not just a one-off model release. It becomes a reusable interface pattern for the next generation of video editors. That is the kind of design shift that tends to outlast a single benchmark cycle.
Official Links And Deployment Paths
| Resource | Why It Matters | Link |
|---|---|---|
| Project page | Best release overview for the model concept and editing workflow. | https://www.yongshengyu.com/Aurora-Page/ |
| arXiv paper | Primary source for the release date, benchmark framing, and method details. | https://arxiv.org/abs/2605.18748 |
| Paper PDF | Best source for the full architecture, evaluation setup, and results. | https://arxiv.org/pdf/2605.18748 |
| GitHub repository | Public implementation path and the clearest README-level description of the agent workflow. | https://github.com/yeates/Aurora |
| Hugging Face paper page | Useful discovery page connecting the release to the current AI paper cycle. | https://huggingface.co/papers/2605.18748 |
Why This Release Matters For The AI Market
Video generation and video editing are moving toward productization fast, but most current systems still assume the user will do the hard setup work for them. They expect exact wording, clean references, and already-localized edit targets. Aurora points in a better direction. It treats user intent resolution as part of the model stack, not as a support burden pushed back onto the creator. That matters because the next durable winners in AI video will likely be the systems that reduce workflow friction, not just the ones that generate prettier clips.
Aurora is also worth watching because the release trail is public enough to inspect. Readers can start with the project page, read the arXiv paper, inspect the paper PDF, and follow the GitHub repository. For an AI news workflow, that is a good sign. It means the story is supported by real technical artifacts rather than only a short teaser and a sample reel.
FAQs
What is Aurora?
Published on May 18, 2026, Aurora introduces an agentic video editing framework that rewrites underspecified user requests into structured edit plans before passing them into a unified video diffusion transformer.
When was Aurora released?
Aurora was published or announced on May 18, 2026.
Why does Aurora matter?
A fresh video-model release from May 18, 2026 deserves attention because it tackles one of the most practical failure points in generative video editing. Aurora is not just another unified video diffusion model. It is an agentic editing stack that pairs a tool-using vision-language model with a video transformer so the system can first resolve what the user actually meant, then execute the edit. That makes the release more useful than a typical benchmark-oriented launch, because real editing prompts are usually incomplete, visually underspecified, or missing assets the model needs.
Where can developers access Aurora?
Aurora can be explored through the official source here: https://arxiv.org/abs/2605.18748.